
Im Mittelstand mit erster KI-Erfahrung entsteht oft folgendes Bild: Drei oder vier KI-Agenten wurden in den letzten zwölf Monaten parallel gebaut. Ein Mail-Triage-Agent in der Sales-Abteilung, ein CRM-Update-Agent in Marketing, ein Angebots-Agent im Vertrieb. Jeder für sich funktioniert. Zusammen funktionieren sie nicht – weil keiner weiß, was der andere gerade tut. Manuelle Übergabe zwischen den Agenten verbrennt den Effizienzgewinn, den die KI bringen sollte.
Eine mehrstufige KI-Verarbeitungskette ist die Antwort darauf. Sie orchestriert mehrere Agenten zu einer Kette, jeder Schritt kennt das Ergebnis des vorigen, der Audit-Trail hält die gesamte Pipeline zusammen. Dieser Satellite zeigt die Architektur einer mehrstufigen KI-Verarbeitungskette im Mittelstand, drei konkrete Industrie-Beispiele und die Verankerung im KI-Betriebssystem. Den übergeordneten Pillar finden Sie unter KI-Betriebssystem im Mittelstand.
Warum eine Pipeline und nicht drei Einzel-Agenten
Stand 2025-2026 erreichen Mehrstufige KI-Verarbeitungsketten mit zentraler Orchestrierung im Schnitt 2.3-fach höhere End-to-End-Automatisierungsraten als Einzel-Agenten. Der Hebel kommt aus drei Quellen. Erstens: keine manuelle Übergabe zwischen Agenten – der Output von Agent A wird automatisch Input von Agent B. Zweitens: zentraler Audit-Trail – jede Stufe der Pipeline ist im Protokoll. Drittens: Fehlerbehandlung pro Stufe – wenn Agent B abbricht, ist der Status von Agent A noch da und der Vorgang kann gerettet werden. Quelle Customer-Factory-Benchmark, n=14 Mittelstand-Pipelines 2024-2026.
Praxisstimme eines Tech-Lead
Ein anonymisierter Tech-Lead eines Maschinenbauers im Service formulierte es so: „Drei isolierte Agenten waren nicht schneller als drei Menschen. Erst die Pipeline mit Protokoll-Schicht (Fachbegriff: Audit-Plane) hat den Unterschied gemacht.“ Der Unterschied liegt nicht in der Modell-Qualität, sondern in der Orchestrierung darunter.
Architektur einer mehrstufigen KI-Verarbeitungskette
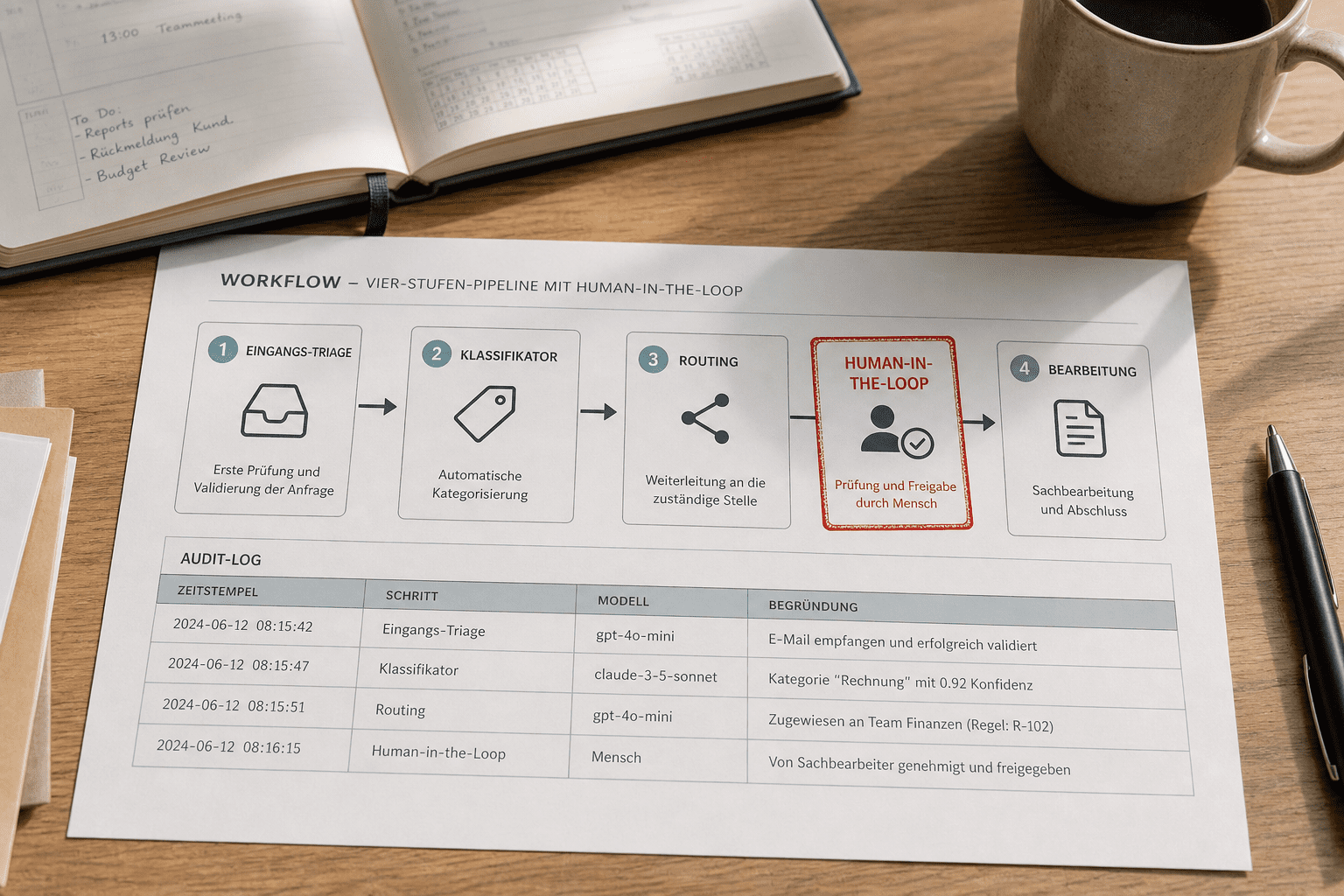
Eine produktive Pipeline im Mittelstand hat fünf Architektur-Bestandteile, die im KI-Betriebssystem zusammenwirken.
- Trigger-Layer: Auslöser einer Pipeline – typischerweise eine eingehende Mail, ein Formular-Submit, ein Webhook aus einem ERP-System oder ein zeitbasierter Cron.
- Orchestrator: Das Gehirn der Pipeline. Definiert die Stufen, leitet den Datenfluss, führt Fehlerbehandlung durch und entscheidet, welcher Agent als nächstes laufen soll.
- Agenten: Die einzelnen Skill-Bausteine aus der Skill-Bibliothek. Jeder Agent hat eine klare Eingabe-Spezifikation und Ausgabe.
- State-Speicher: Der Zwischen-Zustand der Pipeline. Damit kann der Vorgang nach einem Fehler an der richtigen Stelle weiterlaufen.
- Audit-Logger: Protokolliert jeden Pipeline-Schritt mit Eingabe, ausgewähltem Agent, Antwort, Datum und Mitarbeiter-ID, wenn ein Mensch eingegriffen hat.
sensified implementiert diese fünf Bestandteile in der Workflow and Orchestration Plane plus der Audit and Evidence Plane des KI-Betriebssystems. Die einzelnen Agenten kommen aus der Skill-Bibliothek – mehr zu Skill-Engineering unter Skill-Engineering für KI im Mittelstand.
| Stufe | Hauptfunktion | Audit-Eintrag |
|---|---|---|
| Trigger | Pipeline starten | Eingabe-Daten, Quell-System |
| Klassifizierung | Vorgang in Kategorie einordnen | Eingabe, Modell, Kategorie |
| Routing | Nächsten Agenten oder Mensch auswählen | Routing-Entscheidung, Grund |
| Bearbeitung | Inhaltliche Aufgabe lösen | Eingabe, Agent, Antwort |
| Freigabe | Vier-Augen oder Selbst-Freigabe | Freigeber, Zeitpunkt |
| Ausgabe | Antwort an Kunde oder Folge-System | Endgültige Aktion |
Drei Industrie-Beispiele aus Service, Logistik und Versicherung
Maschinenbau-Service mit Störungs-Pipeline
Ein anonymisierter Maschinenbauer mit 240 Mitarbeitenden im Service hatte vorher Diagnose-Agent, Ersatzteil-Agent und Termin-Agent isoliert laufen. Kunden meldeten Störungen, die drei Agenten arbeiteten parallel ohne Wissens-Austausch. Nach Aufbau einer Pipeline: Diagnose-Agent übergibt Fehlercode plus Maschine an Ersatzteil-Agent, dieser an Termin-Agent. Der Status pro Schritt ist in der Protokoll-Schicht sichtbar. Service-Bearbeitungszeit sinkt um 52 Prozent, First-Time-Fix-Rate steigt um 18 Prozentpunkte.
Logistiker mit Frachtanfrage-Pipeline
Ein anonymisierter Logistiker hatte Frachtanfrage-Bearbeitung von durchschnittlich 25 Minuten – fünf Agenten, vier Tools, null Orchestrierung. Nach Pipeline-Aufbau: Inquiry-Agent erfasst Anfrage, Pricing-Agent berechnet, Capacity-Agent prüft Verfügbarkeit, Document-Agent erstellt Vertrag, Confirmation-Agent sendet Bestätigung. Jeder Schritt loggt Entscheidung und Begründung. Time-to-Quote sinkt um 71 Prozent, Disposition-Auslastung steigt um 34 Prozent.
Versicherer mit Schaden-Pipeline
Ein anonymisierter Versicherer im Mittelstand hatte Schadenmeldungen durch sechs manuelle Stationen wandern lassen, KI hängt unkoordiniert an Station zwei. Nach Pipeline-Aufbau: Meldungs-Agent erfasst, Triage-Agent klassifiziert (mit Ampel-Klasse), Routing-Agent wählt Bearbeitungs-Agent oder Mensch (bei Hochrisiko-Schaden Human-in-the-Loop-Pflicht). Bearbeitungszeit sinkt um 41 Prozent, Disclosure-Pflicht nach EU AI Act Artikel 50 wird automatisch erfüllt durch den Audit-Trail. Mehr zur Ampel-Klassifikation unter KI-Governance mit Ampel-System.
Wo der Mensch in der Pipeline eingreift
Im Mittelstand wird häufig die Frage gestellt: Geht eine Pipeline ohne Menschen durch? Die richtige Antwort ist: Nein, und das ist Absicht. Drei Stellen sind Standard für Human-in-the-Loop-Punkte.
Erste Stelle: nach der Klassifizierung. Wenn der Klassifizierungs-Agent unsicher ist oder die Eingabe ausserhalb seiner Trainingsdaten liegt, wird der Vorgang an einen Mitarbeiter weitergeleitet. Zweite Stelle: vor der Freigabe einer außenwirkenden Aktion. Bei Klasse-Gelb-Use-Cases (mit Disclosure-Pflicht) und Klasse-Rot-Use-Cases (mit Vier-Augen-Pflicht) braucht es einen menschlichen Freigeber. Dritte Stelle: bei Eskalation. Wenn ein Bearbeitungs-Agent abbricht oder ein Folge-System einen Fehler meldet, wird der Vorgang an einen Mitarbeiter weitergeleitet.
Diese drei Stellen sind nicht Schwäche der Pipeline, sondern ihre Stärke. Sie machen Compliance möglich und sichern Qualität. DSGVO Artikel 22 (automatisierte Einzelentscheidungen) bleibt sauber adressiert, weil der Mensch bei wesentlichen Entscheidungen die letzte Instanz ist.
Audit-Trail und EU-AI-Act-Compliance
Eine Pipeline ohne Audit-Trail ist Spielzeug. Eine Pipeline mit Audit-Trail ist Compliance-Werkzeug. Konkret protokolliert die Protokoll-Schicht jede Pipeline-Stufe mit Eingabe, ausgewähltem Agent, Antwort, Datum und Freigabe-Status. Bei Pipelines, die EU-AI-Act-relevant sind (Hochrisiko nach Artikel 6 oder Disclosure-pflichtig nach Artikel 50), enthält das Protokoll auch die Modell-Version und die Kontext-Quellen.
Dieser Audit-Trail ist im Auditor-Termin Gold wert. Statt zu erklären, „wir gehen davon aus, dass die KI das Richtige gemacht hat“, wird die exakte Antwort des Modells, der genutzte Kontext und die Freigabe-Entscheidung gezeigt. Die Protokoll-Schicht sensified Audit and Evidence Plane ist auf die EU-AI-Act-Anforderungen ausgelegt.
Mehr zur EU-AI-Act-Compliance und zum Ampel-System für Use-Case-Klassifikation finden Sie unter KI-Governance mit Ampel-System. Quelle EU AI Act offiziell: Verordnung 2024/1689. Anthropic-Forschung zu Multi-Agenten-Systemen unter Building Effective Agents.
Häufige Fehler bei der Pipeline-Implementation
Drei Fehler-Muster zeigen sich im Mittelstand. Erstens: Pipeline ohne Audit-Trail. Wer schnell Pipelines baut und Audit als Nachgedanke plant, hat im Audit-Termin keine Antworten auf die Frage „warum hat die KI das so entschieden“. Korrektur: Protokoll-Schicht vor der ersten Pipeline aktivieren.
Zweitens: zu viele Stufen. Pipelines mit 10 oder mehr Stufen sind im Mittelstand fast immer zu komplex. Wartung wird unmöglich, Fehlerbehandlung wird Vollzeitstelle. Korrektur: Pipelines mit drei bis fünf Stufen sind der Sweet Spot. Wer mehr braucht, baut zwei kürzere Pipelines mit definierter Schnittstelle.
Drittens: keine Test-Sets. Wer eine Pipeline ohne Test-Set deployt, weiß erst beim ersten Kunden-Fehler, dass die Pipeline nicht funktioniert. Korrektur: Test-Set mit zehn Standard-Vorgängen pro Pipeline-Variante, automatisch bei jeder Änderung durchgespielt.
Die Pipeline-Disziplin in einem Satz
Eine produktive mehrstufige KI-Verarbeitungskette im Mittelstand hat drei bis fünf Stufen, einen Audit-Trail in jeder Stufe, zwei oder drei Human-in-the-Loop-Punkte und ein Test-Set mit zehn Standard-Vorgängen. Wer diese vier Punkte hat, baut Pipelines, die im Tagesgeschäft tragen und im Audit-Termin Bestand haben.
Nächste Schritte
Drei Fragen klären, ob eine mehrstufige KI-Verarbeitungskette für das eigene Unternehmen sinnvoll ist. Erstens: Welche zwei oder drei Use-Cases mit mehrstufigem Vorgang werden heute manuell übergeben? Zweitens: Wer kann die Pipeline orchestrieren – Inhouse-Tech-Team oder Plattform-Partner? Drittens: Welche Audit-Anforderungen gibt es im eigenen Sektor (BaFin, VAIT, TISAX, ISO 42001)?
Wer Pipelines als Teil eines vollständigen KI-Betriebssystems plant, findet die übergeordnete Roadmap unter KI-Betriebssystem im Mittelstand. Die Skill-Bibliothek, aus der die Agenten kommen, unter Skill-Engineering für KI im Mittelstand. Die EU-AI-Act-konforme Klassifizierung pro Pipeline unter KI-Governance mit Ampel-System. Die Produkt-Beschreibung von sensified ai-os mit Ablauf-Schicht (Fachbegriff: Workflow-Plane) unter KI-Betriebssystem für Unternehmen im Mittelstand. Ein 30-minütiges Strategiegespräch klärt, welche Ihrer Use-Cases bereit für Pipeline-Orchestrierung sind.
Weiterführende Themen aus dem Cluster
- AI-First Organisation im Mittelstand — Organisationsdesign für KI-getriebene Wertschöpfung.
- AI-Native Transformation im Mittelstand — Vom KI-Tool-Einsatz zur KI-nativen Organisation.
Wählen Sie bitte Ihren Wunschtermin direkt im Kalender aus.
FAQ
- Wie unterscheidet sich eine KI-Agenten-Pipeline von einer klassischen Workflow-Engine?
- Eine klassische Workflow-Engine (z.B. BPMN-Engines) arbeitet mit festen Regeln und vordefinierten Aktionen. Eine KI-Agenten-Pipeline integriert KI-Modelle in einzelne Stufen, sodass jede Stufe kontextabhängig entscheiden kann. Beide können köxistieren – häufig ist die Pipeline das Subsystem innerhalb eines größeren BPMN-Workflows.
- Wie viele Stufen sollte eine KI-Agenten-Pipeline maximal haben?
- Im Mittelstand sind drei bis fünf Stufen das Optimum. Pipelines mit über zehn Stufen werden schwer wartbar und fehleranfällig. Wer mehr Stufen braucht, sollte die Pipeline in zwei kleinere zerlegen, mit definierter Schnittstelle dazwischen.
- Was passiert, wenn ein Agent in der Pipeline ausfällt?
- Der Orchestrator fängt den Fehler ab und entscheidet je nach Konfiguration: Retry mit Standard-Daten, Fallback auf alternativen Agenten, Eskalation an Mitarbeiter oder Stop der gesamten Pipeline. Der State-Speicher hält den Zwischen-Zustand, sodass der Vorgang nach Fehlerbehebung an der richtigen Stelle weiterlaufen kann.
- Wie viele Human-in-the-Loop-Punkte sollte eine Pipeline haben?
- Zwei bis drei sind Standard. Mehr unterbrechen den Effizienzgewinn, weniger sind compliance-riskant. Die Pflicht-Stellen sind: nach unsicherer Klassifizierung, vor außenwirkender Aktion (bei Klasse Gelb und Rot), bei Fehler-Eskalation. Wer nur einen HiL-Punkt hat, sollte die Pipeline nochmal prüfen.
- Wie passt die KI-Agenten-Pipeline zur ISO IEC 42001?
- Die ISO IEC 42001 verlangt dokumentiertes Risikomanagement pro KI-Use-Case. Pipelines werden als einzelner Use-Case behandelt, die Gesamt-Klasse der Pipeline ist die höchste Klasse der einzelnen Agenten. Audit-Trail und Test-Set pro Pipeline erfüllen die Norm-Anforderung an Dokumentation und Qualitätsprüfung.
Weitere Artikel
- KI-Governance 2026
KI-Governance mit Ampel-System: DSGVO- und AI-Act-konform 2026
Mit dem EU AI Act ab 2. August 2026 stehen Mittelständler vor der Pflicht, ihre KI-Use-Cases nach Risiko zu klassifizieren, freizugeben und zu überwachen. Ein Ampel-System…
Weiterlesen →
- Kontext-Layer für KI
Kontext-Layer für KI im Mittelstand: DSGVO-fest und EU-souverän
Mitarbeiter laden Verträge in ChatGPT – der Vertrag landet bei OpenAI. Ein DSGVO-fester Kontext-Layer im KI-Betriebssystem stellt sicher, dass die KI aus Ihrer eigenen Wissensbasis antwortet,…
Weiterlesen →
- Skill-Engineering
Skill-Engineering für KI im Mittelstand: Vom Prompt zum Baustein
Im Mittelstand prompted jede Mitarbeiterin anders, das gleiche Problem wird zwölf Mal neu gelöst. Skill-Engineering ist die Disziplin, aus Einzel-Prompts versionierte, getestete und ownerschaftliche KI-Bausteine zu…
Weiterlesen →
- KI-Betriebssystem Aufbau
KI-Betriebssystem aufbauen: 5 Bausteine für den Mittelstand
Ein KI-Betriebssystem im Mittelstand steht auf fünf Bausteinen, die in einer bewährten Reihenfolge gebaut werden: Identity, Connector, Policy plus Audit, AI Gateway und Knowledge. Dieser Satellite…
Weiterlesen →
- KI-Betriebssystem 2026
KI-Betriebssystem im Mittelstand: Leitfaden, Bausteine, Roadmap 2026
Im Mittelstand stehen heute 15 KI-Tools nebeneinander, ohne gemeinsamen Kontext. Ein KI-Betriebssystem fasst Identität, Policies, Audit, Connectoren, KI-Routing und Wissen in einer Plattform zusammen. Dieser Leitfaden…
Weiterlesen →
- KI-Transformation Automotive
KI-Transformation in der Automobilindustrie: Strategie, System, Wissenstransfer
sensified.ai ordnet, was KI-Transformation in der Automobilindustrie bedeutet, warum Tool-Einkauf keine Transformation ergibt und wie der Weg vom ersten System bis zum Wissenstransfer ins eigene Haus…
Weiterlesen →